

Make sure to use machinectl and not sudo or anything else. That’s about the symptoms I’d expect from an incomplete session setup. The use of machinectl there was very deliberate, as it goes through all the PAM, logind, systemd and D-Bus stuff as any normal login. It gets you a clean and properly registered session, and also gets rid of anything tied to your regular user:
max-p@desktop ~> loginctl list-sessions
SESSION UID USER SEAT LEADER CLASS TTY IDLE SINCE
2 1000 max-p seat0 3088 user tty2 no -
3 1000 max-p - 3112 manager - no -
8 1001 tv - 589069 user pts/4 no -
9 1001 tv - 589073 manager - no -
It basically gets you to a state of having properly logged into the system, as if you logged in from SDDM or in a virtual console. From there, if you actually had just logged in a tty as that user, you could run startplasma-wayland and end up in just as if you had logged in with SDDM, that’s what SDDM eventually launches after logging you in, as per the session file:
max-p@desktop ~> cat /usr/share/wayland-sessions/plasma.desktop
[Desktop Entry]
Exec=/usr/lib/plasma-dbus-run-session-if-needed /usr/bin/startplasma-wayland
TryExec=/usr/bin/startplasma-wayland
DesktopNames=KDE
Name=Plasma (Wayland)
# ... and translations in every languages
From there we need one last trick, it’s to get KWin to start nested. That’s what the additional WAYLAND_DISPLAY=/run/user/1000/wayland-0 before is supposed to do. Make sure that this one is ran within the machinectl shell, as that shell and only that shell is the session leader.
The possible gotcha I see with this, is if startplasma-wayland doesn’t replace that WAYLAND_DISPLAY environment variable with KWin’s, so all the applications from that session ends up using the main user. You can confirm this particular edge case by logging in with the secondary user on a tty, and running the same command including the WAYLAND_DISPLAY part of it. If it starts and all the windows pop up on your primary user’s session, that’s the problem. If it doesn’t, then you have incorrect session setup and stuff from your primary user bled in.
Like, that part is really important, by using machinectl the process tree for the secondary user starts from PID 1:
max-p@desktop ~> pstree
systemd─┬─auditd───{auditd}
├─bash─┬─(sd-pam) # <--- This is the process machinectl spawned
│ └─fish───zsh───fish───zsh # <-- Here I launched a bunch of shells to verify it's my machinectl shell
├─systemd─┬─(sd-pam) # <-- And that's my regular user
│ ├─Discord─┬─Discord───Discord───46*[{Discord}]
│ ├─DiscoverNotifie───9*[{DiscoverNotifie}]
│ ├─cool-retro-term─┬─fish───btop───{btop}
│ ├─dbus-broker-lau───dbus-broker
│ ├─dconf-service───3*[{dconf-service}]
│ ├─easyeffects───11*[{easyeffects}]
│ ├─firefox─┬─3*[Isolated Web Co───30*[{Isolated Web Co}]]
Super weird stuff happens otherwise that I can’t explain other than some systemd PAM voodoo happens. There’s a lot of things that happens when you log in, for example giving your user access to keyboard, mouse and GPU, and the type of session depends on the point of entry. Obviously if you log in over SSH you don’t get the keyboard assigned to you. When you switch TTY, systemd-logind also moves access to peripherals such that user A can’t keylog user B while A’s session is in the background. Make sure the machinectl session is also the only session opened for the secondary user, as it being assigned to a TTY session could also potentially interfere.
what distro/plasma version are you running? (here it’s opensuse slowroll w/ plasma 6.1.4)
Arch, Plasma 6.1.5.
what happens if you just run startplasma-wayland from a terminal as your user? (I see the plasma splash screen and then I’m back to my old session)
You mean a tty or a terminal emulator like Konsole?
- In a tty
- if I’m already logged in it should switch to the current session as multi-instance is not supported
- if it’s my only graphical session, it should start Plasma normally with the only exception being KWallet not unlocking automatically.
- In a terminal within my graphical session: nothing at all.
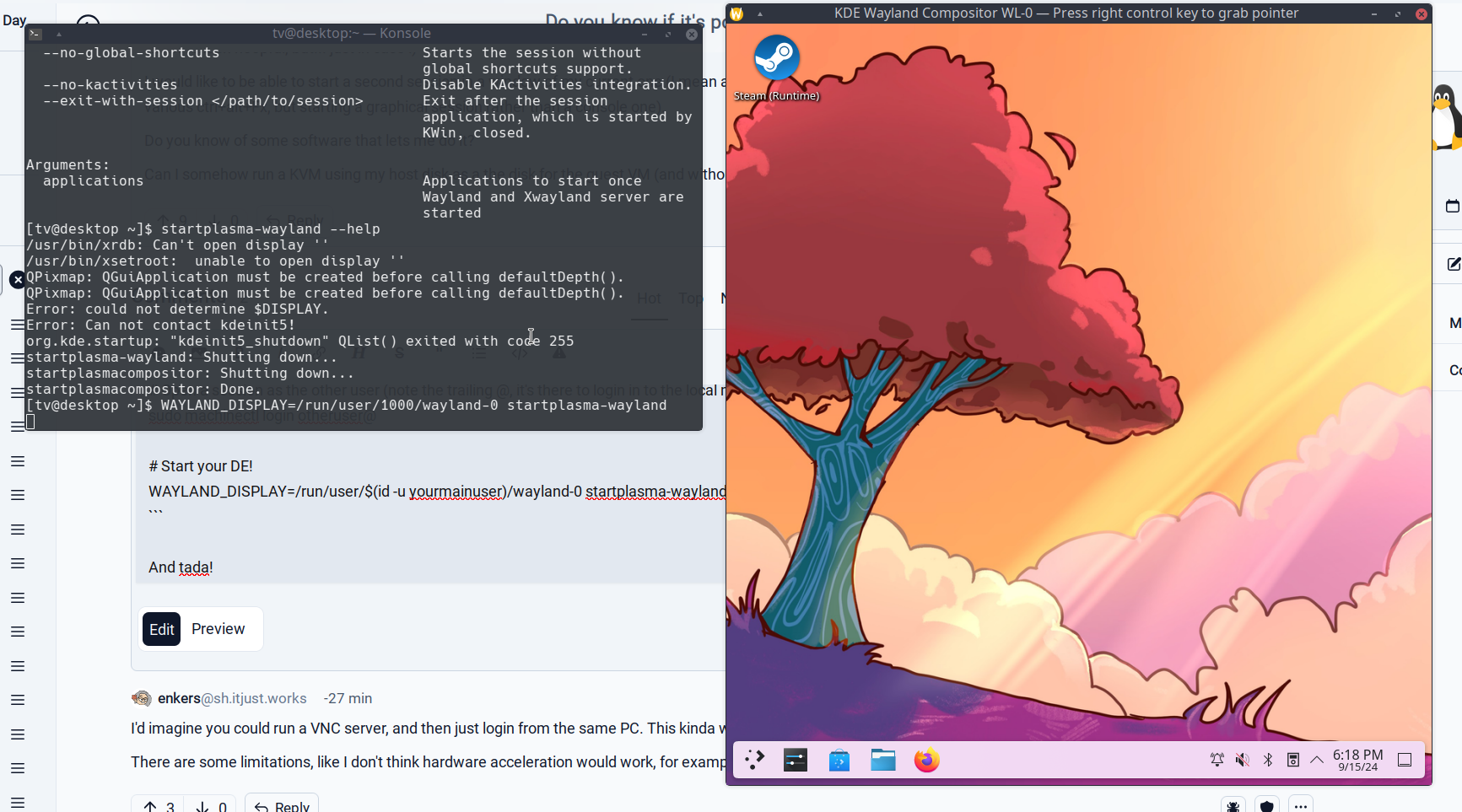



You can also nest rootful Xwayland in there too!
From the user’s shell,
WAYLAND_DISPLAY=/run/user/1000/wayland-0 Xwayland :1 & export DISPLAY=:1 WAYLAND_DISPLAY= i3 & xterm & konsole &Of course you that means you can also run Plasma X11 that way for example: