- 46 Posts
- 2.81K Comments

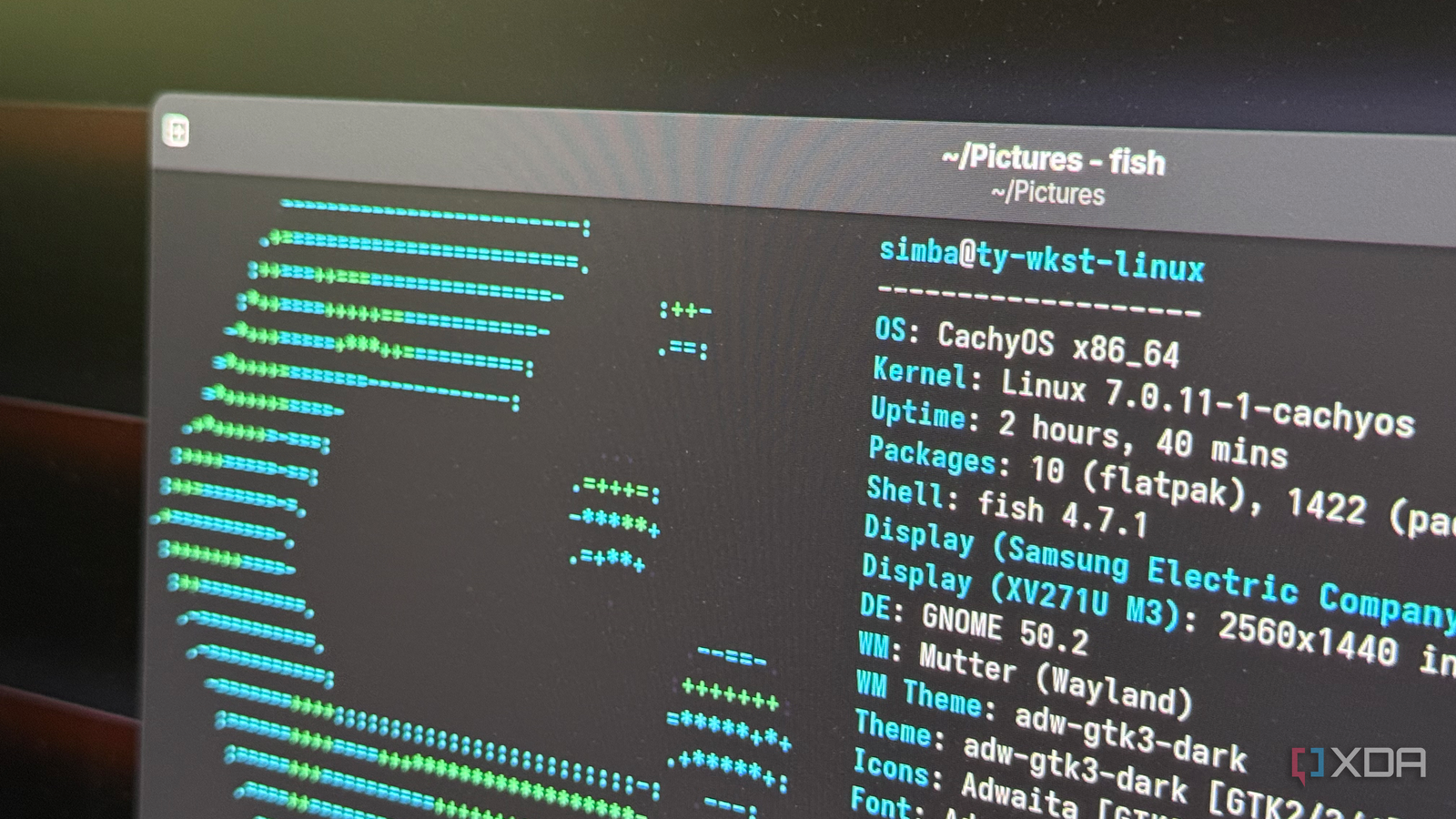

Do you want explain a bit more?
Linux is Linux. If you’re using the standard install packages like Pam, then it’s built specifically for multiple users.
Elaborate more if you could.

 4·8 days ago
4·8 days agoYou seem to have zero knowledge on the subject, so let me educate you a lil bit:
Data isn’t treated like physical evidence.
Drugs and weapons are physical evidence.
US laws do not cover any protections of ephemeral (non-physical) evidence pertaining to crimes committed ex post facto: meaning law enforcement is not privy to any and all collection of said data if not in scope for a crime committed, unlike…PHYSICAL EVIDENCE.
You can see drugs. You can hold drugs. Law enforcement can make a reasonable assumption that someone shooting a gun in public is breaking the law and seize that gun, because they are actually breaking the law (juris laws dependent) by firing the gun.
If suddenly our laws allowed the assumption that whatever exists on a phone for a random person in public contains something related to a crime, police would be able to stop anyone and everyone on the street everywhere and take their phone or data for simply thinking every person is suspicious. This is why the 4th amendment exists, and why police are enot allowed to do such things. His is why warrants are a thing.
Read up.
Did you read the article and the laws pertaining to data seizure at the border? Crossing the border doesn’t constitue an investigation of ANY kind, and also doesn’t suddenly conjure up some sort of suspicion that a crime is in progress or has been committed, meaning no pretense for charges because PERSONAL DATA was not seized. Good lawd.
Again…you can SEARCH all you want. Whether you find anything is not mandated.
I’m not sure what’s so hard to understand about this.
In your Section A right there: “official proceeding”
There was no crime in progress, suspicious activity, or active charges brought against this person.
Maybe reread the article.
Also, Police do not bring charges, Prosecuting Attorneys do. Police are only responsible for investigations and arresting. Everything else is cleared by the legal system first.
It does not depend. 4th amendment is superceded by any state law, and it’s SUPER clear that unless a crime has been committed and prosecutorial procedures are in place, no search or seizure is legal.
That’s the whole point.
Yes, and only JUDGES are able to make that determination.
There is no stature in Federal or State law that says this is a crime, and no superceded precedent for this.
Yeah, you’re wrong in a number of different ways. No, you’re not a lawyer.
What you linked to is precedent par notice. Every single subordinate literally mentions notice.
A law enforcement officer of ANY type is not able able to issue that notice.
Search is not the same thing. Search means they CAN legally search. It absolutely does mean that wiping your phone prevented, obstructed, or obscured a SEARCH. Search all you fucking want, that data is gone. It’s not retroactively comparable.
That being said, had there been a judge that said “You can’t wipe your phone, because you are being charged with a crime, and we believe there is evidence of this crime on your phone, and here is why…”
Way different, and these laws only exist to prevent law enforcement from being caught in a cyclical legal roundabout in court related to the 4th amendment, and even then, many defense lawyers get “gray area” material data evidence thrown out because of Miranda Rights, or illegal searches by law enforcement of data harvested when the defendent was not properly advised or advocated for their ability to refuse.
Murderers get off for this shit because Cops get overzealous and don’t follow the letter of the law or chain of custody in evidentiary collection.
Perfectly legal. Unless they were legally charged and ordered by a court to preserve data considered to be used in a crime, they can’t be charged with shit. Cops don’t dictate this, courts do, AND that scope only applies to an active prosecution anyway.
 1·14 days ago
1·14 days agoJust post a picture of your beard and official Autism Certificate FFS.
Jesus fuck.
MAC is for your local network.
Hostname is not relevant because the endpoints you’re connecting to are not doing reverse lookups.
Your Public IP from your ISP is all they see. They’ve also blocked VPN endpoint IP address space.
They aren’t tracking you through software on your machine, just the global address space. Best you can do is see if your ISP has IP6 space you can be attached to, because they don’t have a good way to block that yet.
Just plain old Fedora is probably what you want. Run it on two Framework laptops with Zero issues.
 12·15 days ago
12·15 days agoPeople who just look at the title and not the description.
 5·16 days ago
5·16 days agoThat’s fine, but there is literally zero benefit except a flex. All the people claiming better security clearly do not understand how a kernel works, let alone a multi-faceted kernel like this, and what memory even means in relation to a monolith that sort of behaves like a microkernel.
Clever as fuck
Debian will work fine. Force a terminal down if needed, but skip the GDM.
Be more specific about what you need. Modern kernel, desktop, data rescue tools…etc?



What’s your point? Nix is meant for CI, but even still the defaults are set for multi-user operations.