Github has really turned to shit. Almost every time I try to search for something I get the too many requests error even if it’s the first time I’ve visited the site in a week.
It would be nice if people could self host something like Forgejo, but the damn AI crawlers will just hammer your server until it crashes. The crawlers are really hard to block without relying on another big tech company like Cloudflare.
It’s hard to host anything public without relying on something like cloudflare.
But, what makes you say it’s “ai crawlers” rather than conventional botnets and so on? Very few organisations have the resources to train large ai models, but the resources needed to run a botnet or something are much lower.
The botnets usually try to login to SSH and pages like phpmyadmin & wp-admin looking for something they can infect rather than scraping every single page on a website frequently. Unless you do something to become the target of a DDoS attack or don’t secure your server, they usually aren’t much more than a source of log spam.
My issue is with the scrapers pretending to be something they aren’t. Tens of thousands of requests, spread over IPs, mostly from China and Singapore but increasingly from South America.
AmazonBot follows robots.txt. I don’t so what Huawei and Azure ASNs have to do with it - that sounds like those requests simply come from inside a Huawei and an Azure network, respectively, but could otherwise be anything.

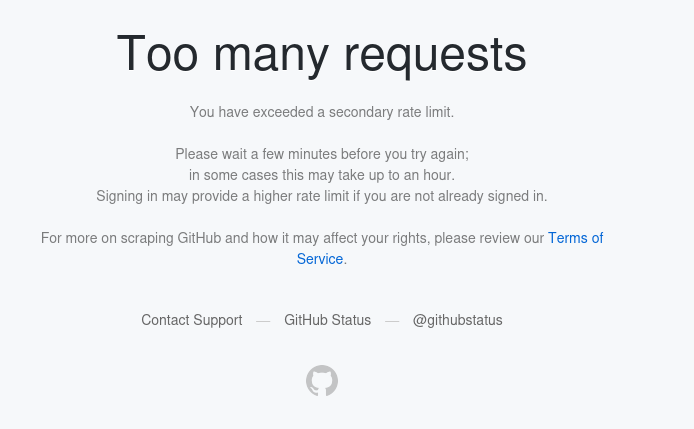
Github has really turned to shit. Almost every time I try to search for something I get the too many requests error even if it’s the first time I’ve visited the site in a week.
It would be nice if people could self host something like Forgejo, but the damn AI crawlers will just hammer your server until it crashes. The crawlers are really hard to block without relying on another big tech company like Cloudflare.
It’s hard to host anything public without relying on something like cloudflare.
But, what makes you say it’s “ai crawlers” rather than conventional botnets and so on? Very few organisations have the resources to train large ai models, but the resources needed to run a botnet or something are much lower.
The botnets usually try to login to SSH and pages like phpmyadmin & wp-admin looking for something they can infect rather than scraping every single page on a website frequently. Unless you do something to become the target of a DDoS attack or don’t secure your server, they usually aren’t much more than a source of log spam.
Because the 1000 requests/10 minutes on my server are done by AmazonBot, mostly. Followed by ASNs from Huawei, Azure and the like.
If big tech are the issue, then try this robots.txt (yes on github…): https://github.com/ai-robots-txt/ai.robots.txt
My issue is with the scrapers pretending to be something they aren’t. Tens of thousands of requests, spread over IPs, mostly from China and Singapore but increasingly from South America.
AmazonBot follows
robots.txt. I don’t so what Huawei and Azure ASNs have to do with it - that sounds like those requests simply come from inside a Huawei and an Azure network, respectively, but could otherwise be anything.He just repeats what he heard elsewhere, he doesn’t really understand what the words mean, just fancy text prediction